| Aula Didattica "G. Taliercio" |
| Introduzione all'uso del laboratorio didattico |
| a cura del dott. Roberto Valli |
|
Indice | Precedente | Successivo 3. Il
file system
Il concetto centrale del sistema Linux, così come dei sistemi UNIX in generale, è quello di file. Possiamo dire genericamente che un file è un insieme di byte organizzati in sequenza e identificato da un nome. Ai fini di questa introduzione distinguerò 3 tipi principali di file: normali: sono i normali file di testo, di dati, i programmi eseguibili, i programmi sorgente; directory: sono dei file particolari che contengono solo riferimenti ad altri file. Una directory è quella che in altri sistemi operativi viene chiamata "cartella", siamo soliti dire che una directory, o una cartella contiene dei file, ma in realtà la directory contiene i riferimenti a dei file, ovvero consente al sistema operativo di individuarli; speciali: sono nomi simbolici che rappresentano i dispositivi hardware collegati al nostro elaboratore, come dischi fissi, floppy disk, stampanti, lettori di CD-ROM, ecc. Per poter utilizzare i file è necessario un meccanismo che
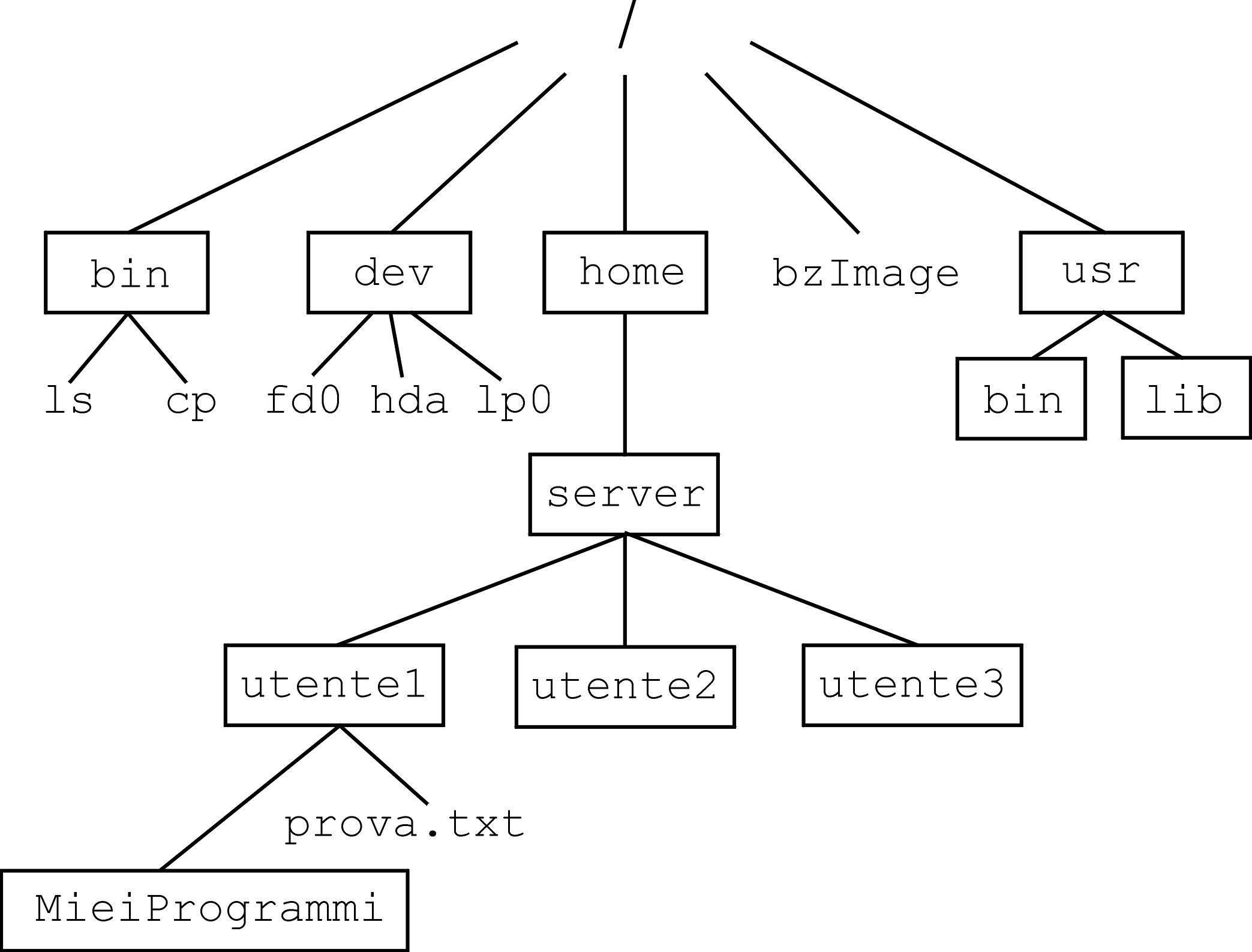
Questo meccanismo è il file system, ovvero una struttura di file organizzata gerarchicamente secondo uno schema ad albero, a grafo orientato. Il punto di partenza è la directory radice (/) o root directory che si sviluppa in rami e nodi; la radice è il nodo principale dell'albero, i rami rappresentano il collegamento dei nodi successivi con quello di origine, i nodi successivi possono essere directory, file di dati o file di altro genere. Se il nodo successivo è costituito da una directory, da questo possono uscire altri rami che rappresentano il collegamento tra directory e file o tra directory e directory. Questo tipo di organizzazione gerarchica consente l'individuazione univoca di un file in base ad un percorso logico; infatti è possibile tracciare il cammino che lo congiunge alla directory radice passando attraverso una catena di sottodirectory, o nodi successivi del nostro albero. Questo cammino prende il nome di percorso o path e si esprime come una sequenza di nomi separati da una barra obliqua (/).
Il percorso server/utente1/MieiProgrammi rappresenta un attraversamento dei nodi server, utente1 e MieiProgrammi. Dal momento che il nostro albero ha un nodo di origine corrispondente alla radice, si possono distinguere due tipi di percorsi: relativo e assoluto. Percorso relativo. Un percorso è relativo quando parte dalla posizione corrente dell'albero per raggiungere la destinazione desiderata. Nel caso dell'esempio, server/utente1/MieiProgrammi, si partiva dalla posizione corrente, server, e venivano attraversati i due nodi successivi, discendenti del primo. Percorso assoluto. Un percorso è assoluto quando parte dalla radice /, cioè dall'origine del file system. Quindi se volessimo esprimere il percorso assoluto per arrivare alla directory (nodo) MieiProgrammi, dovremmo scrivere /home/server/utente1/MieiProgrammi. In questa struttura ad albero ogni nodo ha un genitore (una directory genitore), può avere dei discendenti (delle sottodirectory), e il nodo radice rappresenta l'origine. Quando in un percorso si vuole tornare indietro verso il nodo genitore, non si usa il nome di questo, ma un simbolo speciale rappresentato da due punti in sequenza (..), che rappresenta appunto la directory gerarchicamente superiore. Un altro simbolo, il punto singolo (.), sta ad indicare, invece, la posizione corrente, ovvero il nodo in cui mi trovo. Per cui se mi trovo nella directory server e voglio indicare il percorso necessario a raggiungere la directory MieiProgrammi, posso scrivere, in maniera equivalente, server/utente1/MieiProgrammi oppure ./server/utente1/MieiProgrammi
|