
 Parallel Computer Centre
Parallel Computer Centre
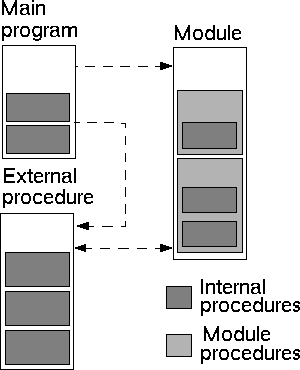
The following illustrates the relationship between the different types of program units:
Dividing a program into units has several advantages:
PROGRAM [name]
[specification statements]
[executable statements]
...
[CONTAINS
internal procedures]
END [PROGRAM [name]]
The PROGRAM statement marks the beginning of the main program unit while the END PROGRAM statement not only marks the end of the unit but also the end of the program as a whole. The name of the program is optional but advisable. The CONTAINS statement serves to identify any procedures that are internal to the main program unit. (Internal procedures are dealt with later on in this chapter.) When all executable statements are complete, control is passed over any internal procedures to the END statement.
A program can be stopped at any point during its execution, and from any program unit, through the STOP statement:
STOP [label]
where label is an optional character string (enclosed in quotes) which may be used to inform the user why and at what point the program has stopped.
procedure name [(argument list)]
[specification statements]
[executable statements]
...
[CONTAINS
internal procedures]
END procedure [name]
where procedure may be either SUBROUTINE or FUNCTION.
There are several different types of procedure:
CALL name [( argument list )]
result = name [( argument list )]
In both cases control is passed to the procedure from the referencing statement, and is returned to the same statement when the procedure exits. The argument list are zero or more variables or expressions, the values of which are used by the procedure.
An argument list is simply a number of variables or expressions (or even procedure names - see later). The argument(s) in a referencing statement are called actual arguments, while those in the corresponding procedure statement are call dummy arguments. Actual and dummy argument are associated by their position in a list, i.e the first actual argument corresponds to the first dummy argument, the second actual argument with the second dummy argument, etc. The data type, rank, etc. of actual and dummy arguments must correspond exactly.
When a procedure is referenced data is copied from actual to dummy argument(s), and is copied back from dummy to actual argument(s) on return. By altering the value of a dummy argument, a procedure can change the value of an actual argument.
REAL, DIMENSION(10) :: a, c
...
CALL swap( a,c )
SUBROUTINE swap( a,b )
REAL, DIMENSION(10) :: a, b, temp
temp = a
a = b
b = temp
END SUBROUTINE swap
The subroutine swap exchanges the contents of two real arrays.
REAL :: y,x,c
...
y = line( 3.4,x,c )
FUNCTION line( m,x,const )
REAL :: line
REAL :: m, x, const
line = m*x + const ! always assign a value to the function id.
END FUNCTION line
The function line calculates the value of y from the equation of a straight line. The name of the function, line, is treated exactly like a variable, it must be declared with the same data type as y and is used to store the value of the function result.
Note that in both examples, the name of a dummy argument may be the same as or different from the name of the actual argument.
Internal procedures may only be referenced by their host and other procedures internal to the same host, although internal procedures may invoke other (external and module) procedures.
For example:
PROGRAM outer
REAL :: a, b, c
...
CALL inner( a )
...
CONTAINS
SUBROUTINE inner( a ) !only available to outer
REAL :: a !passed by argument
REAL :: b=1.0 !redefined
c = a + b !c host association
END SUBROUTINE inner
END PROGRAM outer
The program outer contains the internal subroutine inner. Note that variables defined in the host unit remain defined in the internal procedure, unless explicitly redefined there. In the example, although a, b and c are all defined in outer:
PROGRAM first
REAL :: x
x = second()
...
END PROGRAM first
FUNCTION second() !external
REAL :: second
... !no host association
END FUNCTION second
External procedures have no host program unit, and cannot therefore share data through host association. Passing data by argument is the most common way of sharing data with an external procedure. External procedures may be referenced by all other types of procedure.
Variables declared inside a procedure usually only exist while the procedure in question is executing:
FUNCTION func1( a_new )
REAL :: func1
REAL :: a_new
REAL, SAVE :: a_old !saved
INTEGER :: counter=0 !saved
...
a_old = a_new
counter = counter+1
END FUNCTION func1
The first time the function func1 is referenced, a_old has an undefined value while counter is set to zero. These values are reset by the function and saved so that in any subsequent calls a_old has the value of the previous argument and counter is the number of times func1 has previously been referenced.
Note: it is not possible to save dummy arguments or function results!
INTERFACE
interface statements
END INTERFACE
The interface block for a procedure is included at the start of the referencing program unit. The interface statements consist of a copy of the SUBROUTINE (or FUNCTION) statement, all declaration statements for dummy arguments and the END SUNROUTINE (or FUNCTION) statement. For example:
PROGRAM count
INTERFACE
SUBROUTINE ties(score, nties)
REAL :: score(50)
INTEGER :: nties
END SUBROUTINE ties
END INTERFACE
REAL, DIMENSION(50):: data
...
CALL ties(data, n)
...
END PROGRAM count
SUBROUTINE ties(score, nties)
REAL :: score(50)
INTEGER :: nties
...
END SUBROUTINE ties
The interface block in the program count provides an explicit interface to the subroutine ties. If the count were to reference other external procedures, their interface statements could be placed in the same interface block.
Since it is often the case that a program may wish to pass different sized arrays or character strings to the same procedure, Fortran 90 allows dummy arguments to have a variable sizes. Such objects are call assumed shape objects. For example:
SUBROUTINE sub2(data1, data3, str)
REAL, DIMENSION(:) :: data1
INTEGER, DIMENSION(:,:,:) :: data3
CHARACTER(len=*) :: str
...
The dummy arguments data1 and data3 are both arrays which have been declared with a rank but no size, the colon `:' is used instead of a specific size in each dimension. Similarly str has no explicit length, it adopts the length of the actual argument string. When the subroutine sub2 is called, all three dummy arguments assume the size of their corresponding actual arguments; all three dummy arguments are assumed shape objects.
SUBROUTINE invert(a, inverse, count)
REAL, INTENT(IN) :: a
REAL, INTENT(OUT) :: inverse
INTEGER, INTENT(INOUT) :: count
inverse = 1/a
count = count+1
END SUBROUTINE invert
The subroutine invert has three dummy arguments. a is used in the procedure but is not updated by it and therefore has INTENT(IN). inverse is calculated in the subroutine and so has INTENT(OUT). count (the number of times the subroutine has been called) is incremented by the procedure and so requires the INTENT(INOUT) attribute.
SUBROUTINE sub2(a, b, stat)
INTEGER, INTENT(IN) :: a, b
INTEGER, INTENT(INOUT):: stat
...
END SOBROUTINE sub2
could be referenced using the statements:
INTEGER :: x=0
...
CALL sub2( a=1, b=2, stat=x )
CALL sub2( 1, stat=x, b=2)
CALL sub2( 1, 2, stat=x )
The dummy variable names act as keywords in the call statement. Using keywords, the order of arguments in a call statement can be altered, however keywords must come after all arguments associated by position:
CALL sub2( 1, b=2, 0 ) !illegal
CALL sub2( 1, stat=x, 2) !illegal
When using keyword arguments the interface between referencing program unit and procedure must be explicit. Note also that arguments with the INOUT attribute must be assigned a variable and not just a value, stat=0 would be illegal.
SUBROUTINE sub1(a, b, c, d)
INTEGER, INTENT(INOUT):: a, b
REAL, INTENT(IN), OPTIONAL :: c, d
...
END SUBROUTINE sub1
Here a and b are always required when calling sub1. The arguments c and d are optional and so sub1 may be referenced by:
CALL sub1( a, b )
CALL sub1( a, b, c, d )
CALL sub1( a, b, c )
Note that the order in which arguments appear is important (unless keyword arguments are used) so that it is not possible to call sub1 with argument d but no argument c. For example:
CALL sub1( a, b, d ) !illegal
Optional arguments must come after all arguments associated by position in a referencing statement and require an explicit interface.
It is possible to test whether or not an optional argument is present when a procedure is referenced using the logical intrinsic function PRESENT. For example:
REAL :: inverse_c
IF( PRESENT(c) ) THEN
inverse_c = 0.0
ELSE
inverse_c = 1/c
ENDIF
If the optional argument is present then PRESENT returns a value .TRUE. In the above example this is used to prevent a run-time error (dividing by zero will cause a program to `crash').
PROGRAM test
INTERFACE
REAL FUNCTION func( x )
REAL, INTENT(IN) ::x
END FUNCTION func
END INTERFACE
...
CALL sub1( a, b, func(2) )
...
END PROGRAM test
REAL FUNCTION func( x ) !external
REAL, INTENT(IN) :: x
func = 1/x
END FUNCTION func
When the call to sub1 is made the three arguments will be a, b and the result of func, in this case the return value is 1/2. The procedure that is used as an argument will always execute before the procedure in whose referencing statement it appears begins. Using a procedure as an argument requires an explicit interface.
Note that the specification statement for the function func identifies the result as being of type REAL, this is an alternative to declaring the function name as a variable, i.e.
REAL FUNCTION func( x )
REAL, INTENT(IN) :: x
func = 1/x
END FUNCTION func
and
FUNCTION func( x )
REAL :: func
REAL, INTENT(IN) :: x
func = 1/x
END FUNCTION func
are equivalent.
RECURSIVE FUNCTION factorial( n ) RESULT(res)
INTEGER, INTENT(IN) :: n
INTEGER :: res
IF( n==1 ) THEN
res = 1
ELSE
res = n*factorial( n-1 )
END IF
END FUNCTION factorial
Recursion may be one of two types:
Recursive procedures require careful handling. It is important to ensure that the procedure does not invoke itself continually. For example, the recursive procedure factorial above uses an IF construct to either call itself (again) or return a fixed result. Therefore there is a limit to the number of times the procedure will be invoked.
For convenience, Fortran 90 allows two or more procedures to be referenced by the same, generic name. Exactly which procedure is invoked will depend on the data type (or rank) of the actual argument(s) in the referencing statement. This is illustrated by some of the intrinsic functions, for example:
The SQRT() intrinsic function (returns the square root of its argument) can be given a real, double precision or complex number as an argument:
INTERFACE swap
SUBROUTINE iswap( a, b )
INTEGER, INTENT(INOUT) :: a, b
END SUBROUTINE iswap
SUBROUTINE rswap( a, b )
REAL, INTENT(INOUT) :: a, b
END SUBROUTINE rswap
END INTERFACE
The interface specifies two subroutines iswap and rswap which can be called using the generic name swap. If the arguments to swap are both real numbers then rswap is invoked, if the arguments are both integers iswap is invoked.
While a generic interface can group together any procedures performing any task(s) it is good programming practice to only group together procedures that perform the same operation on a different arguments.
The general form of a module follows that of other program units:
MODULE name
[definitions]
...
[CONTAINS
module procedures]
END [MODULE [name]]
In order to make use of any definitions, data or procedures found in a module, a program unit must contain the statement:
USE name
at its start.
Using modules it is possible to place declarations for all global variables within a module and then USE that module. For example:
MODULE global
REAL, DIMENSION(100) :: a, b, c
INTEGER :: list(100)
LOGICAL :: test
END MODULE global
All variables in the module global can be accessed by a program unit through the statement:
USE global
The USE statement must appear at the start of a program unit, immediately after the PROGRAM or other program unit statement. Any number of modules may be used by a program unit, and modules may even use other modules. However modules cannot USE themselves either directly (module A uses A) or indirectly (module A uses module B which uses module A).
It is possible to limit the variables a program unit may access. This can act as a `safety feature', ensuring a program unit does not accidentally change the value of a variable in a module. To limit the variables a program unit may reference requires the ONLY qualifier, for example:
USE global, ONLY: a, c
This ensures that a program unit can only reference the variables a and c from the module global. It is good programming practice to USE ... ONLY those variables which a program unit requires.
A potential problem with using global variables are name clashes, i.e. the same name being used for different variables in different parts of the program. The USE statement can overcome this by allowing a global variable to be referenced by a local name, for example:
USE global, state=>test
Here the variable state is the local name for the variable test. The => symbol associates a different name with the global variable.
Module procedures have the same form as external procedures, that is they may contain internal procedures. However unlike external procedures there is no need to provide an interface in the referencing program unit for module procedures, the interface to module procedures is implicit.
Module procedures are invoked as normal (i.e. through the CALL statement or function reference) but only by those program units that have the appropriate USE statement. A module procedure may call other module procedures within the same module or in other modules (through a USE statement). A module procedure also has access to the variables declared in a module through `host association'. Note that just as with other program units, variables declared within a module procedure are local to that procedure and cannot be directly referenced elsewhere.
One of the main uses for a module is to group together data and any associated procedures. This is particularly useful when derived data types and associated procedures are involved. For example:
MODULE cartesian
TYPE point
REAL :: x, y
END TYPE point
CONTAINS
SUBROUTINE swap( p1, p2 )
TYPE(point), INTENT(INOUT):: p1
TYPE(point), INTENT(INOUT):: p2
TYPE(point) :: tmp
tmp = p1
p1 = p2
p2 = tmp
END SUBROUTINE swap
END MODULE cartesian
The module carteasian contains a declaration for a data type called point. cartesian also contains a module subroutine which swaps the values of its point data type arguments. Any other program unit could declare variables of type point and use the subroutine swap via the USE statement, for example:
PROGRAM graph
USE cartesian
TYPE(point) :: first, last
...
CALL swap( first, last)
...
END PROGRAM graph
The PRIVATE statement/attribute prevents access to module entities from any program unit, PUBLIC is the opposite. Both may and be used in a number of ways:
MODULE one
PRIVATE !set the default for module
REAL, PUBLIC :: a
REAL :: b
PUBLIC :: init_a
CONTAINS
SUBROUTINE init_a() !public
...
SUBROUTINE init_b() !private
...
END MODULE one
INTERFACE generic_name
MODULE PROCEDURE name_list
END INTERFACE
where name_list are the procedures to be referenced via generic_name, for example a module containing generic subroutines to swap the values of two arrays including arrays of derived data types would look like:
MODULE cartesian
TYPE point
REAL :: x, y
END TYPE point
INTERFACE swap
MODULE PROCEDURE pointswap, iswap, rswap
END INTERFACE
CONTAINS
SUBROUTINE pointswap( a, b )
TYPE(point) :: a, b
...
END SUBROUTINE pointswap
!subroutines iswap and rswap
END MODULE cartesian
Operator overloading is best defined in a module and requires an interface block of the form:
INTERFACE OPERATOR( operator )
interface_code
END INTERFACE
where operator is the operator to be overloaded and the interface_code is a function with one or two INTENT(IN) arguments. For example:
MODULE strings
INTERFACE OPERATOR ( / )
MODULE PROCEDURE num
END INTERFACE
CONTAINS
INTEGER FUNCTION num( s, c )
CHARACTER(len=*), INTENT(IN) :: s
CHARACTER, INTENT(IN) :: c
num = 0
DO i=1,LEN( s )
IF( s(i:i)==c ) num=num+1
END DO
END FUNCTION num
END MODULE strings
Usually, the / operator is not defined for characters or strings but the module strings contains an interface and defining function to allow a string to be divide by a character. The result of the operation is the number of times the character appears in the string:
USE strings
...
i = `hello world'/'l' !i=3
i = `hello world'/'o' !i=2
i = `hello world'/'z' !i=0
MODULE cartesian
TYPE point
REAL :: x, y
END TYPE point
INTEFACE OPERATOR ( .DIST. )
MODULE PROCEDURE dist
END INTERFACE
CONTAINS
REAL FUNCTION dist( a, b )
TYPE(point) INTENT(IN) :: a, b
dist = SQRT( (a%x-b%x)**2 + (a%y-b%y)**2 )
END FUNCTION dist
END MODULE cartesian
The operator .DIST. is used to find the distance between two points. The operator is only defined for the data type point, using it on any other data type is illegal. Just as with overloaded operators, the interface and defining function are held in a module. It makes sense to keep the derived data type and associated operator(s) together.
Any program unit may make use of the data type point and the operator .DIST. by using the module cartesian, for example:
USE cartesian
TYPE(point) :: a, b
REAL :: distance
...
distance = a .DIST. b
MODULE cartesian
TYPE point
REAL :: x, y
END TYPE point
INTEFACE ASSIGNMENT( = )
MODULE PROCEDURE max_point
END INTERFACE
CONTAINS
SUBROUTINE max_point( a, pt )
REAL, INTENT(OUT) :: a
TYPE(point), INTENT(IN) :: pt
a = MAX( pt%x, pt%y )
END SUBROUTINE max_point
END MODULE cartesian
Using the module cartesian allows a program unit to assign a type point to a type real. The real variable will have the largest value of the components of the point variable. For example:
USE cartesian
TYPE(point) :: a = point(1.7, 4.2)
REAL :: coord
...
coord = a !coord = 4.2
The scope of a name (for say a variable) declared in a program unit is valid from the start of the unit through to the unit's END statement. The scope of a name declared in the main program or in an external procedure extends to all internal procedures unless redefined by the internal procedure. The scope of a name declared in an internal procedure is only the internal procedure itself - not other internal procedures.
The scope of a name declared in a module extends to all program units that use that module, except where an internal procedure re-declares the name.
The names of program units are global and must therefore be unique. The name of a program unit must also be different from all entities local to that unit. The name of an internal procedure extends throughout the containing program unit. Therefore all internal procedures within the same program unit must have different names.
The following shows an example of scoping units:
MODULE scope1 !scope 1
... !scope 1
CONTAINS !scope 1
SUBROUTINE scope2() !scope 2
TYPE scope3 !scope 3
... !scope 3
END TYPE scope3 !scope 3
INTERFACE !scope 3
... !scope 4
END INTERFACE !scope 3
REAL :: a, b !scope 3
10 ... !scope 3
CONTAINS !scope 2
FUNCTION scope5() !scope 5
REAL :: b !scope 5
b = a+1 !scope 5
10 ... !scope 5
END FUNCTION !scope 5
END SUBROUTINE !scope 2
END MODULE !scope 1
a) Write an internal function which requires no actual arguments, but which uses host association to access the value to be converted. The result of the function is the converted temperature.
b) Write an external function which requires the temperature to be converted to be passed as a single argument. Again the function result is the converted temperature. Do not forget to include an interface block in the main program.
Use the following formula to convert from Fahrenheit to Centigrade: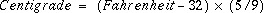
a) Write an internal subroutine which requires no actual arguments, but which uses host association to access the array to be sorted.
b) Write an external subroutine which requires that the array to be sorted be passed as an argument. The external subroutine will require an interface block.
Use the following selection sort algorithm to sort the values in an array a:
INTEGER :: a(5), tmp
INTEGER :: j, last, swap_index(1)
last = SIZE( a )
DO j=1, last-1
swap_index = MINLOC( a(j:last) )
tmp = a( j )
a( j ) = a( (j-1)+swap_index(1) )
a( (j-1)+swap_index(1) ) = tmp
END DO
The selection sort algorithm passes once through the array to be sorted, stopping at each element in turn. At each element the remainder of the array is checked to find the element with the minimum value, this is then swapped with the current array element.
The subroutine is to replace any values in the array greater than top with the value of top; similarly the subroutine replaces any values lower than tail with tail. The values of top and tail are read in by the main program. If either top or tail is absent on call then no respective action using the value is taken. (Remember it is good programming practice to refer to all optional arguments by keyword.)
The module should also contain a function to calculate the distance between two arbitrary points (this is done earlier in the notes, as an operator). Write a program to read in an x and y coordinate and calculate its distance from the origin.