
 Parallel Computer Centre
Parallel Computer Centre
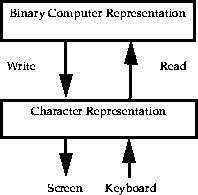
The process of I/O can be summarised as:
The internal hexadecimal representation of a real number may be
BE1D7DBF
which corresponds to the real value
0.000450
which may be written as
-0.45E-03
This conversion of the internal representation to a user readable form is known as formatted I/O and choosing the exact form of the character string is referred to as formatting. The formatting of I/O is the underlying theme of much of this module.
Consider the I/O statements used in the previous modules:
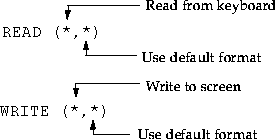
READ (*,100) i, j
WRITE (*,100) i, j
READ (*,FMT=200) x, y
WRITE (*,200) x, y
.....
100 FORMAT (2I)
200 FORMAT (2F10.6)
Formatting is sometimes known as I/O editing. The I/O is controlled using edit descriptors. The general form of a FORMAT statement is
label FORMAT (flist)
where flist is a list of edit descriptors which include
I,F,E,ES,EN,D,G,L,A,H,T,TL,TR,X,P,BN,BZ,SP,SS,S,/,:,',(,)
only the following will be covered
I,F,E,ES,EN,A,X,/,:,',(,)
Many edit descriptors can be prefixed by a repeat count and suffixed with a fieldwidth. Thus in the two examples given above, 2I and 2F10.6, could be described as two integers and two floating-point real numbers with fieldwidths of 10.6 (a description follows).
The labelled FORMAT statement may be replaced by specifying the format descriptor list as a character string directly in the WRITE or READ statement, as follows:
READ (*,'(2I)') I, J
WRITE (*,'(2F12.6)') X, Y
This has the advantage of improved clarity, i.e. the reader does not have to look at two statements which may not be consecutive in the source listing to determine the effect of the I/O statement. However, format descriptor lists may be used by more than one I/O statement and a labelled format statement reduces the risk of introducing inconsistencies between the multiple instances of the descriptor list.
a repeat count
w width of field - total number of characters
m number of digits
d digits to right of decimal point
e number of digits in exponent
The I/O statement will use as many of the edit descriptors as it requires to process all the items in the I/O list. Processing will terminate at the next edit descriptor which requires a value from the I/O list.
WRITE (6,`(I10.6)`) 56would ouput two spaces followed by 0056
WRITE(6,`(2F12.6)`) 12.6, -131.4567891would output ^^^12.600000 and -131.456789 where ^ represents a space
INTEGER, DIMENSION(10) :: A
READ (*,*) I(1), I(2), I(3)
READ (*,*) I
READ (*,*) I(1:3)
Array elements may only appear once in an I/O list, for example:
INTEGER :: I(10), K(3)
K = (/1,2,1/)
READ (*,*) I(K)
would be illegal as I(1) appears twice.
TYPE POINT
REAL X, Y
END TYPE
TYPE TRIANGLE
TYPE (POINT) A, B, C
END TYPE
the following two statements are equivalent
READ (*,*) P, T
READ (*,*) P%X, P%Y, T%A%X, T%A%Y, T%B%X, T%B%Y, T%C%X, T%C%Y
An object of a derived data type which contains a pointer may not appear in an I/O list. This restriction prevents problems occurring with recursive data types.
Any pointers in an I/O list must be associated with a target, the target is the data on which the I/O statement operates, for example:
REAL, POINTER :: PTRA, PTRB
REAL, TARGET :: X
X = 10.0
PTRA => X
WRITE (*,*) PTRA
would output the value 10.0, whereas
WRITE (*,*) PTRB
would generate an error as PTRB is not associated with a target.
(do-object-list, do-var=expr,expr[,expr])
This syntax is similar to the simple indexed DO loop described earlier. Consider the following examples:
INTEGER :: J
REAL, DIMENSION(10) :: A
READ (*,*) (A(J),J=1,10)
WRITE (*,*) (A(J), J=10,1,-1)
The first statement would read 10 values in to each element of I. The second statement would write all 10 values of I in reverse order. The implied-do-list may also be nested
INTEGER :: I, J
REAL, DIMENSION(10,10) :: B
WRITE (*,*) ((B(I,J),I=1,10), J=1,10)
Note:
The NAMELIST statement is used to define a group of variables as follows:
NAMELIST namelist-spec
where namelist-spec is
/namelist-group-name/ variable-name-list
for example
NAMELIST /WEEK/ MON, TUES, WED,THURS, FRI
The list may extended within the same scoping unit by repeating the namelist-group-name on more than one statement, as follows:
NAMELIST /WEEK/ SAT, SUN
More than one group may be defined in one NAMELIST statement but this feature should not be used. Variables should be declared before appearing in a NAMELIST group. Variables with the PRIVATE and PUBLIC attributes should not appear in the same namelist-group. The namelist-group may be used in place of the format specifier in an I/O statement. Only the WRITE statement is considered here.
WRITE (*,NML=WEEK)
will produce
&WEEK SUN=1, MON=2, TUES=3, ...../
where
INTEGER :: SUN, MON, TUES, .....
SUN = 1
MON = 2
.....
Note the output record is an annotated list of the form:
& namelist-group-name namelist-variable=value {,namelist-variable=value} /
This record format must be used for input.
Arrays may also be specified, for example
INTEGER, DIMENSION(10) :: ITEMS
NAMELIST /GROUP/ ITEMS
ITEMS(1) = 1
WRITE (*, NML=GROUP)
would produce
& GROUP ITEMS(1)=1, ITEMS(2:10)=0 /
There is a complex set of rules covering the use of non-advancing I/O and its various associated keywords. This section only deals with the screen management aspects of this topic.
The ADVANCE keyword is used in write or read statements as follows:
READ(*,*,ADVANCE='YES') ...
WRITE (*,*, ADVANCE='NO') ....
There are two optional keywords, EOR and SIZE, which have the form:
EOR=eor-label
SIZE=integer-variable
The EOR keyword specifies a labelled statement to which control is passed if an error occurs (see ERR keyword later) or if the end of record is encountered. The SIZE keyword specifies an integer variable which is set to the number of characters read.
By default unfilled characters in an input record are padded out with blank characters but these characters are not included in the value assigned to SIZE. The PAD keyword to the OPEN statement (see later) may be used to override the default action.
Examples.
(i)
WRITE(*,*,ADVANCE='NO') 'Enter new value: '
READ(*,*) I
If the user enters the value 10 this would appear on the screen as
Enter new value: 10
(ii)
CHARACTER(LEN=32) :: filename
INTEGER :: length
bb: DO
WRITE (*,*, ADVANCE='NO') 'Filename? '
READ(*,*,ADVANCE='NO',EOR=20, SIZE=length) filename
OPEN(10, FILE=filename(1:length),..)
EXIT bb
20 WRITE(*,'(/A,I)') 'Error: maximum length exceeded.',length
END DO
REAL :: a, b, c
REAL, DIMENSION (1:5) :: array
INTEGER :: i, j, k
READ(*,*) a, b, c
READ (*,*) i, j, k, array
given the following input records:
1.5 3.4 5.6 3 6 65
2*0 45
3*23.7 0 0
REAL :: a
CHARACTER(LEN=2) :: string
LOGICAL :: ok
READ (*,'(F10.3,A2,L10)') a, string, ok
what would be read into a, string and ok if the following input records
were used?
(a) bbb5.34bbbNOb.true.
(b) 5.34bbbbbbYbbFbbbbb
(b) b6bbbbbb3211bbbbbbT
(d) bbbbbbbbbbbbbbbbbbF
where b represents a space or blank character.
Hint: An implied DO loop is useful when grouping array elements on the same line.
Write a program which will initialise all the elements of a suitably declared array to 123.456789 and will test the output statements you have just written. What would happen if the initial value was -123456789.789?
'(3F6.4,I5)'
3.40 5.6 7.9 10
4.52 6.3 3.2 11
99.9 0 0 0
'(F6.1,I10)'
4.23 9
5.89 6
99.9 0